Storage (TrueNas, and USB controllers) (Day 13-15)
What started as needing storage turned into a deep dive into USB and storage performances, and lessons about things like UASP, unstable drive paths, and temperamental USB controllers.


This started as a simple "let's set up a container registry".
Instead, it turned into a deep dive into USB architecture, storage performance, and a lesson in why not all USB controllers are created equal, that lasted a whole weekend.
The Registry
I needed to set up a container registry, which meant thinking about storage. The options were:
- Use storage on the K8s VMs and let Longhorn handle replication
- Go with external storage
The registry actually supports using S3 as a backend for image storage. But well cloud providers aren't in the budget, so the next best thing is Minio. I had recently got my hands on two 12TB drives (waiting on a third for RAIDZ1), so this seemed like a perfect use case.
But there was a catch - I'm running mini PCs. No fancy drive bays, or PCIE expansion slots etc, just USB. And this marks the beginning of a very long rabbit hole learning about USB and PCIE devices and things i had no idea about.
UASP
The first bit of good news was that my external enclosure supports USB 3.2 Gen 2 and UASP (USB Attached SCSI Protocol). If you are like me you had no idea what UASP was:
- It's basically a protocol that gets you closer to native SCSI/SATA performance.
- And supports parallel commands and better command queuing, making it behave more like direct disk access.
You can see this in with lsusb -t:
/: Bus 10.Port 1: Dev 1, Class=root_hub, Driver=xhci_hcd/1p, 10000M
| Port 1: Dev 2, If 0, Class=Hub, Driver=hub/4p, 10000M
| Port 1: Dev 3, If 0, Class=Mass Storage, Driver=uas, 10000M
| Port 2: Dev 4, If 0, Class=Mass Storage, Driver=uas, 10000M
| Port 4: Dev 5, If 0, Class=Mass Storage, Driver=uas, 10000MSee that Driver=uas?.
USB Controllers
Digging deeper into the USB setup with lspci -k | grep -i usbwe see:
06:00.3 USB controller: Advanced Micro Devices, Inc. [AMD] Rembrandt USB4 XHCI controller #3
06:00.4 USB controller: Advanced Micro Devices, Inc. [AMD] Rembrandt USB4 XHCI controller #4
07:00.0 USB controller: Advanced Micro Devices, Inc. [AMD] Rembrandt USB4 XHCI controller #8
07:00.3 USB controller: Advanced Micro Devices, Inc. [AMD] Rembrandt USB4 XHCI controller #5
07:00.4 USB controller: Advanced Micro Devices, Inc. [AMD] Rembrandt USB4 XHCI controller #6Okay so I have USB 4 ports, cool, but little did I know these weren't all created equal...
TrueNAS
Getting TrueNAS set up was straightforward enough - grab ISO, upload to Proxmox, create VM (using q35, UEFI, disabled memory ballooning), install.
Now the "fun" started when trying to get the drives to the VM.
Attempt 1: The PCIe passthrough
First attempt: pass through the USB controller as a PCIe device.
So looking at our lsusb -t command we see we see we have:
- Root hub (Bus 10)
- A physical USB hub connected to it
- Three storage devices through that hub
To find which PCI device controls a USB bus we do a readlink /sys/bus/usb/devices/usb10 which shows:
../../../devices/pci0000:00/0000:00:08.3/0000:07:00.4/usb10
This path shows:
- USB Bus 10
- Controlled by PCI device 07:00.4
IOMMU Groups
IOMMU groups show which devices can be passed through independently.
So checking IOMMU groups with find /sys/kernel/iommu_groups/ -type l | grep "0000:07:00":
/sys/kernel/iommu_groups/26/devices/0000:07:00.0
/sys/kernel/iommu_groups/27/devices/0000:07:00.3
/sys/kernel/iommu_groups/28/devices/0000:07:00.4So if I understand this correctly it means each device in its own group can be passed through independently.
I passed through the device in group 28 with "all functions" enabled. The drives disappeared from Proxmox (expected), but so did a bunch of other stuff (kind of makes sense given the PCI thing has other things attached to it not just the USB controller).
However the VM wouldn't even boot (interesting):
error writing '1' to '/sys/bus/pci/devices/0000:07:00.0/reset': Inappropriate ioctl for device failed to reset PCI device '0000:07:00.0', but trying to continue as not all devices need a reset error writing '1' to '/sys/bus/pci/devices/0000:07:00.3/reset': Inappropriate ioctl for device failed to reset PCI device '0000:07:00.3', but trying to continue as not all devices need a reset error writing '1' to '/sys/bus/pci/devices/0000:07:00.4/reset': Inappropriate ioctl for device failed to reset PCI device '0000:07:00.4', but trying to continue as not all devices need a reset kvm: ../hw/pci/pci.c:1633: pci_irq_handler: Assertion `0 <= irq_num && irq_num < PCI_NUM_PINS' failed. TASK ERROR: start failed: QEMU exited with code 1looking at what "all functions" is about it looks like it basically says "Pass everything about this device through"
So I unchecked "all functions" (which gave the host some of the previous "disappeared" devices) and the VM started.
Created a pool, everything seemed fine until:
Critical
Pool test state is SUSPENDED: One or more devices are faulted in response to IO failuresWell, that's not good, this usually suggests disk or hardware issues.
TrueNAS UI also shows the pool is in an unhealthy state
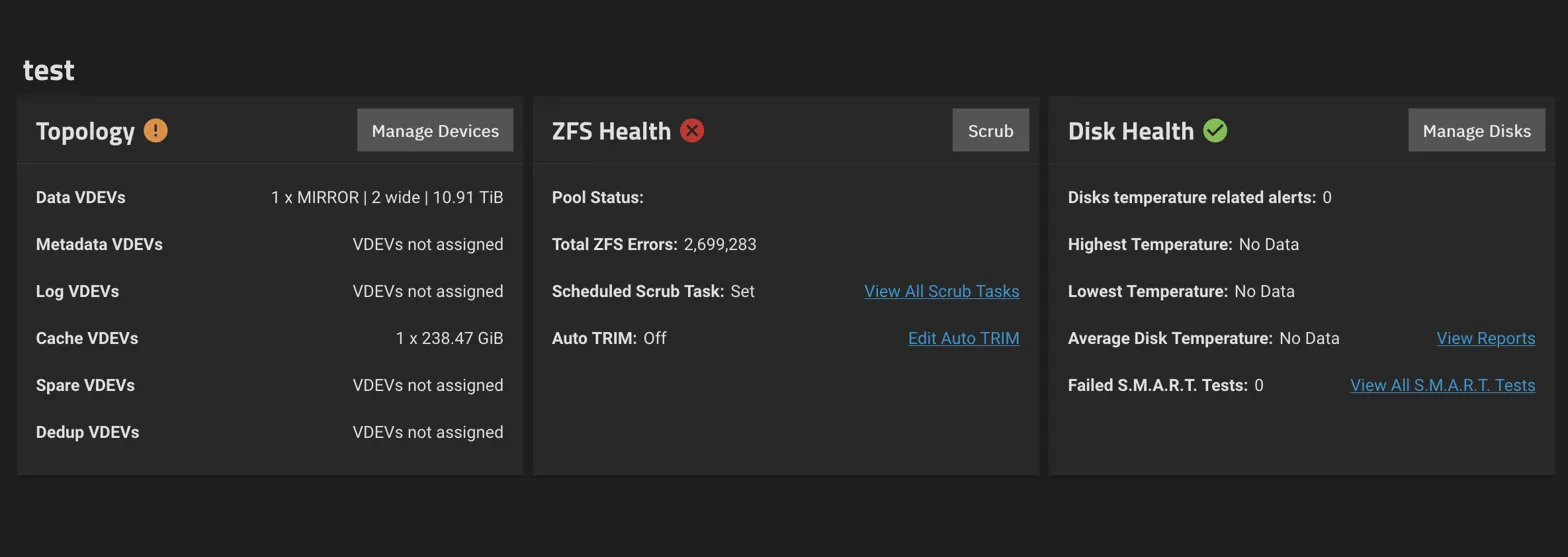
I go to the console and check the status zpool status test and
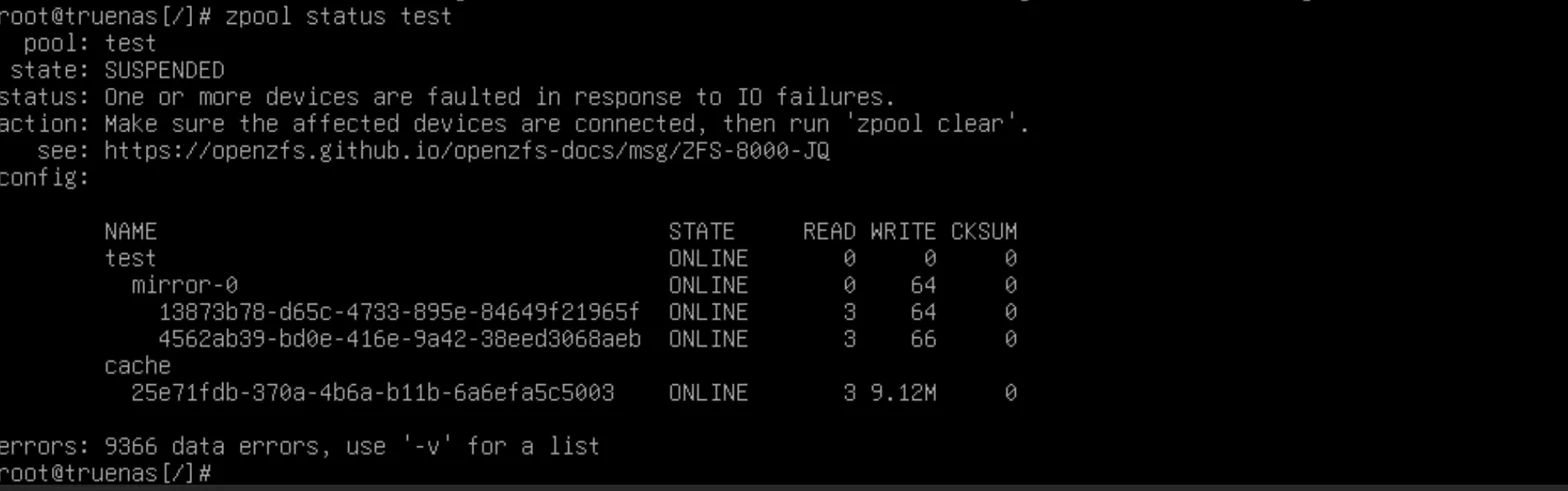
and check the errors on dmesg dmesg | grep -i error
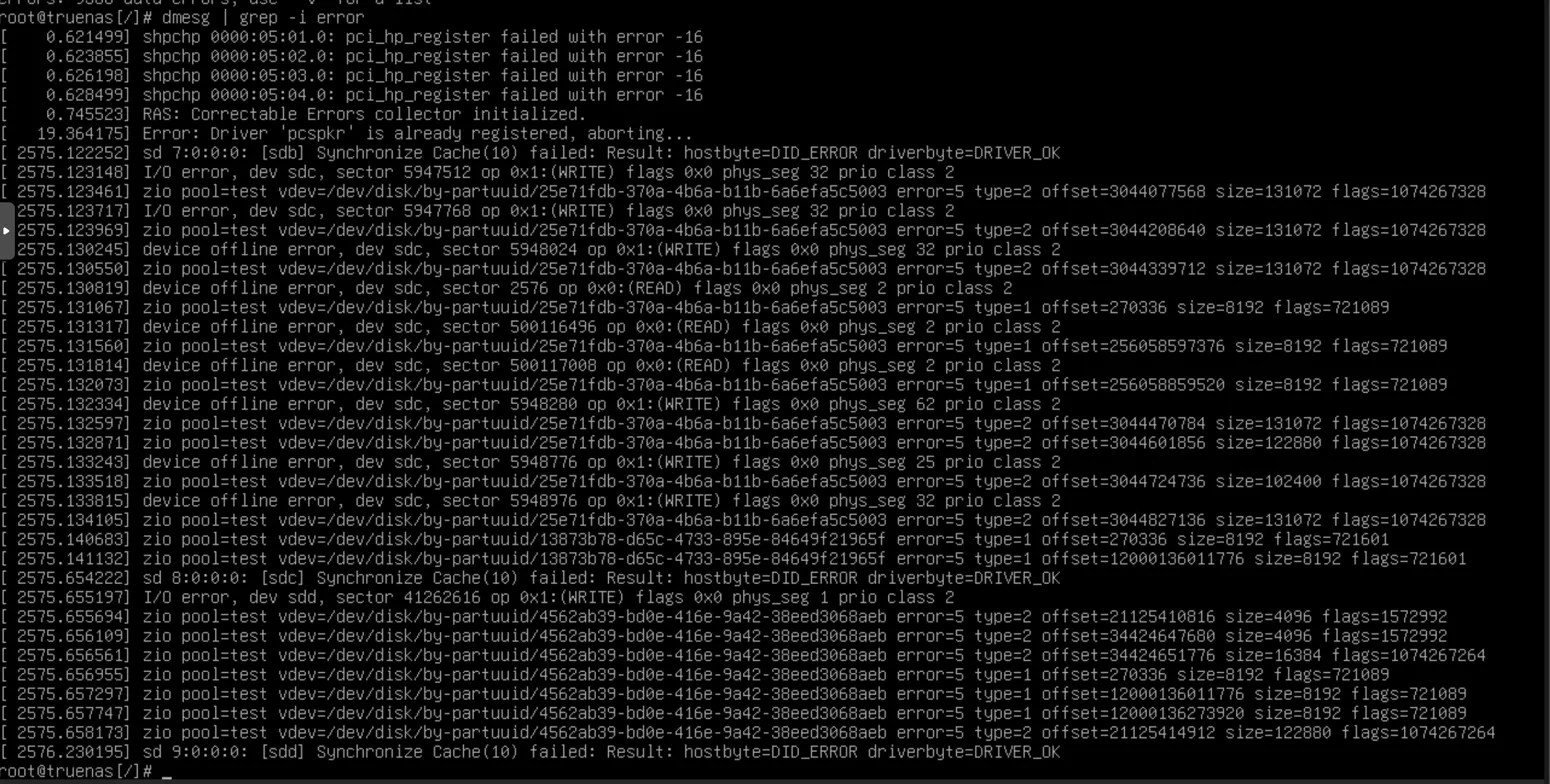
so:
- I've got a lot of I/O errors on the device
sdc, both reads and writes - The pool is in a SUSPENDED state with 9366 data errors
- The mirror seems to still be ONLINE but there are serious I/O issues
I try a smartctl and lsblk, to see what's up with sdc and the drive has disappeared (this also happened for the other drives later).
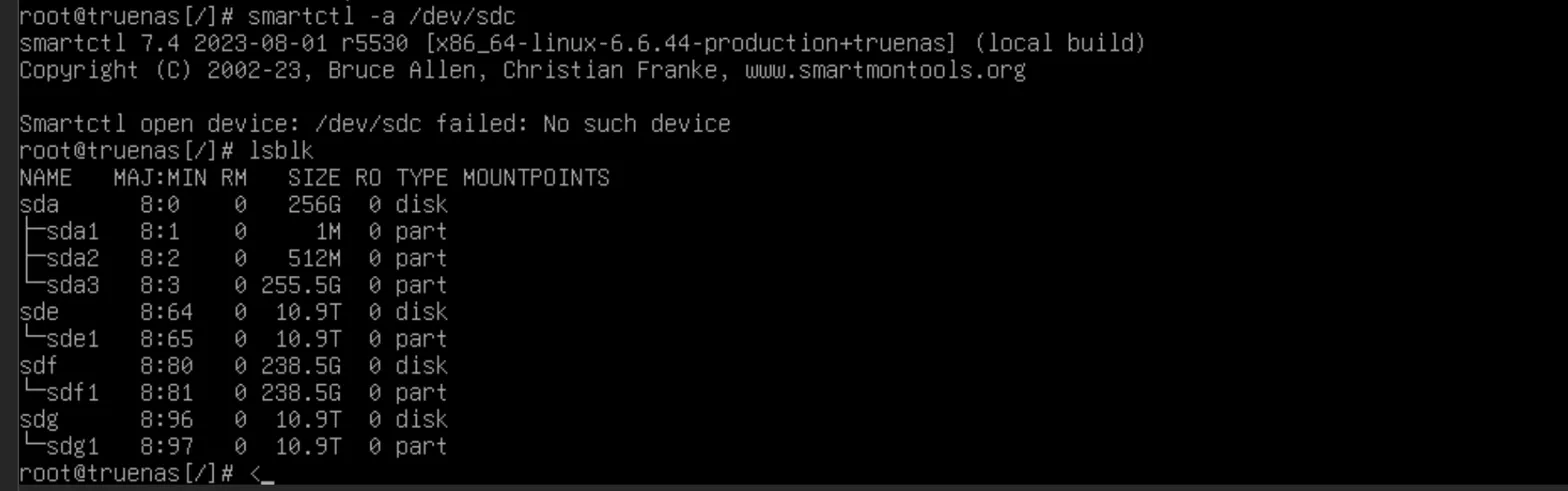
No sdc and the errors are full of references to sdc. This suggests the drive was present (as sdc) when the errors started occurring, but has since completely disappeared from the system - which could mean:
- The drive physically disconnected (Which I didn't do)
- The USB/SATA connection failed
- The drive completely failed and is no longer being recognized (This would suck)
I do an ls -l /dev/disk/by-id/ and confirm the drives are still there, using different names.
usb-ASMT_<serial>-0:0 -> sde
usb-ASMT_<serial>-0:0 -> sdf
usb-ASMT_<serial>-0:0 -> sdgSo remember when I said all USB and USB controllers are not made the same?
After hours of debugging it turns out that under heavy load the USB controller on the port I was using would "crash" and the drives would "shift around", getting remounted with different paths. (There's is more to this)
Not exactly ideal for a storage system.
So I went looking for ways to have TrueNAS use drives wwn instead of the dev path but could not find anything that helped.
Attempt 2: Direct Disk Passthrough
Time for Plan B. Instead of passing through the controller, pass through individual drives.
Install lshw and do an lshw -class disk -class storage to see the drives and their serial numbers.
Do an ls -l /dev/disk/by-id and copy the wwn path or the ata path of the drives.
1. Get drive info:
➜ ~ ls -l /dev/disk/by-id
total 0
lrwxrwxrwx 1 root root 9 Jan 26 20:16 ata-<name-with-serial-number> -> ../../sde
lrwxrwxrwx 1 root root 9 Jan 26 20:16 ata-<name-with-serial-number> -> ../../sdd
lrwxrwxrwx 1 root root 9 Jan 26 20:16 ata-<name-with-serial-number> -> ../../sdf2. Set up SCSI drives:
then using the wwn path or the ata path set scsi drives with the following command:
qm set <vm-id> -scsi1 /dev/disk/by-id/ata-<name-with-serial-number>
qm set <vm-id> -scsi2 /dev/disk/by-id/ata-<name-with-serial-number>
qm set <vm-id> -scsi3 /dev/disk/by-id/ata-<name-with-serial-number>3. Add serial numbers to config:
➜ ~ vim /etc/pve/qemu-server/<vm-id>.conf
... other config
scsi1: /dev/disk/by-id/ata-<name-with-serial-number>,size=11176G,serial=<serial-number>
scsi2: /dev/disk/by-id/ata-<name-with-serial-number>,size=11176G,serial=<serial-number>
scsi3: /dev/disk/by-id/ata-<name-with-serial-number>,size=250059096K,serial=<serial-number>
... other configon the proxmox GUI, you should see the drives are attached and the serial numbers are set under the hardware tab.
And then found if I moved the USB cable to the USB-C port it fixed the flakiness seen when using the other albeit still USB 4 ports.
Performance Testing
To make sure this works I did some stress tests with fio and well the results speak for themselves:
Cache performance
Reading a 10G file in 3.89 seconds (2632MiB/s throughput):
fio --name=test --rw=read --bs=1m --size=10g --filename=./testfile
test: (g=0): rw=read, bs=(R) 1024KiB-1024KiB, (W) 1024KiB-1024KiB, (T) 1024KiB-1024KiB, ioengine=psync, iodepth=1
fio-3.33
Starting 1 process
Jobs: 1 (f=1): [R(1)][75.0%][r=2639MiB/s][r=2638 IOPS][eta 00m:01s]
test: (groupid=0, jobs=1): err= 0: pid=7607: Sun Jan 26 05:46:15 2025
read: IOPS=2632, BW=2632MiB/s (2760MB/s)(10.0GiB/3890msec)
clat (usec): min=352, max=1613, avg=379.02, stdev=30.05
lat (usec): min=352, max=1613, avg=379.07, stdev=30.06
clat percentiles (usec):
| 1.00th=[ 359], 5.00th=[ 363], 10.00th=[ 367], 20.00th=[ 367],
| 30.00th=[ 371], 40.00th=[ 371], 50.00th=[ 375], 60.00th=[ 379],
| 70.00th=[ 383], 80.00th=[ 388], 90.00th=[ 396], 95.00th=[ 404],
| 99.00th=[ 441], 99.50th=[ 465], 99.90th=[ 562], 99.95th=[ 1090],
| 99.99th=[ 1467]
bw ( MiB/s): min= 2604, max= 2650, per=100.00%, avg=2633.71, stdev=16.18, samples=7
iops : min= 2604, max= 2650, avg=2633.71, stdev=16.18, samples=7
lat (usec) : 500=99.79%, 750=0.12%, 1000=0.03%
lat (msec) : 2=0.07%
cpu : usr=0.28%, sys=99.49%, ctx=86, majf=0, minf=266
IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued rwts: total=10240,0,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs):
READ: bw=2632MiB/s (2760MB/s), 2632MiB/s-2632MiB/s (2760MB/s-2760MB/s), io=10.0GiB (10.7GB), run=3890-3890msec
Bigger file and Direct I/O
A bigger file and adding --direct=1 to the command to go around the RAM cache
Reading a 50G file in 129 seconds (396MiB/s throughput):
fio --name=test --rw=read --bs=1m --size=50g --filename=./bigtest --direct=1
test: (g=0): rw=read, bs=(R) 1024KiB-1024KiB, (W) 1024KiB-1024KiB, (T) 1024KiB-1024KiB, ioengine=psync, iodepth=1
fio-3.33
Starting 1 process
test: Laying out IO file (1 file / 51200MiB)
Jobs: 1 (f=1): [R(1)][100.0%][r=267MiB/s][r=267 IOPS][eta 00m:00s]
test: (groupid=0, jobs=1): err= 0: pid=9526: Sun Jan 26 05:54:51 2025
read: IOPS=396, BW=396MiB/s (415MB/s)(50.0GiB/129239msec)
clat (usec): min=133, max=180737, avg=2522.21, stdev=3642.09
lat (usec): min=133, max=180738, avg=2522.37, stdev=3642.10
clat percentiles (usec):
| 1.00th=[ 149], 5.00th=[ 194], 10.00th=[ 212], 20.00th=[ 260],
| 30.00th=[ 799], 40.00th=[ 1500], 50.00th=[ 1876], 60.00th=[ 2245],
| 70.00th=[ 2737], 80.00th=[ 3458], 90.00th=[ 5997], 95.00th=[ 8029],
| 99.00th=[ 12387], 99.50th=[ 16712], 99.90th=[ 34341], 99.95th=[ 45876],
| 99.99th=[116917]
bw ( KiB/s): min=51200, max=2932736, per=100.00%, avg=406019.97, stdev=193023.81, samples=258
iops : min= 50, max= 2864, avg=396.50, stdev=188.50, samples=258
lat (usec) : 250=17.75%, 500=11.38%, 750=0.74%, 1000=1.46%
lat (msec) : 2=21.94%, 4=30.99%, 10=13.34%, 20=2.05%, 50=0.31%
lat (msec) : 100=0.02%, 250=0.02%
cpu : usr=0.14%, sys=10.08%, ctx=37023, majf=0, minf=269
IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued rwts: total=51200,0,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs):
READ: bw=396MiB/s (415MB/s), 396MiB/s-396MiB/s (415MB/s-415MB/s), io=50.0GiB (53.7GB), run=129239-129239msec
Okay, I could live with those numbers as long as they are stable and consistent.
Sustained Operations
So I do 5 runs of reading an 800G file (which does include a write during initial file creation) and and writing 900G file, with a mix of both reading and writing at the same time.
The idea is to see if something breaks, so i'm also monitoring the logs and drive temps
I will maybe never experience this kind of thing in one go unless during a resilver so if this is stable I'm good with that
I leave these running and go have a drink with a some friends, it's the weekend after all.
Reading an 800G file:
fio --name=read --rw=read --bs=1m --size=800g --filename=./bigtest
read: (g=0): rw=read, bs=(R) 1024KiB-1024KiB, (W) 1024KiB-1024KiB, (T) 1024KiB-1024KiB, ioengine=psync, iodepth=1
fio-3.33
Starting 1 process
Jobs: 1 (f=1): [R(1)][100.0%][r=310MiB/s][r=310 IOPS][eta 00m:01s]
read: (groupid=0, jobs=1): err= 0: pid=10516: Sun Jan 26 21:32:56 2025
read: IOPS=255, BW=256MiB/s (268MB/s)(800GiB/3205833msec)
clat (usec): min=356, max=303293, avg=3911.61, stdev=6703.53
lat (usec): min=356, max=303293, avg=3911.78, stdev=6703.52
clat percentiles (usec):
| 1.00th=[ 416], 5.00th=[ 429], 10.00th=[ 437], 20.00th=[ 457],
| 30.00th=[ 506], 40.00th=[ 603], 50.00th=[ 676], 60.00th=[ 3982],
| 70.00th=[ 4555], 80.00th=[ 5276], 90.00th=[ 11731], 95.00th=[ 12387],
| 99.00th=[ 20579], 99.50th=[ 24773], 99.90th=[ 77071], 99.95th=[125305],
| 99.99th=[198181]
bw ( KiB/s): min=43008, max=555008, per=100.00%, avg=261727.05, stdev=73610.29, samples=6411
iops : min= 42, max= 542, avg=255.54, stdev=71.87, samples=6411
lat (usec) : 500=29.19%, 750=21.95%, 1000=0.45%
lat (msec) : 2=1.53%, 4=7.32%, 10=24.63%, 20=13.79%, 50=0.95%
lat (msec) : 100=0.12%, 250=0.07%, 500=0.01%
cpu : usr=0.10%, sys=13.54%, ctx=402475, majf=0, minf=269
IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued rwts: total=819200,0,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs):
READ: bw=256MiB/s (268MB/s), 256MiB/s-256MiB/s (268MB/s-268MB/s), io=800GiB (859GB), run=3205833-3205833msec
and writing a 900G file:
fio --name=write --rw=write --bs=1m --size=900g --filename=./big2testfile
write: (g=0): rw=write, bs=(R) 1024KiB-1024KiB, (W) 1024KiB-1024KiB, (T) 1024KiB-1024KiB, ioengine=psync, iodepth=1
fio-3.33
Starting 1 process
Jobs: 1 (f=1): [W(1)][100.0%][w=216MiB/s][w=216 IOPS][eta 00m:00s]
write: (groupid=0, jobs=1): err= 0: pid=24687: Sun Jan 26 23:32:36 2025
write: IOPS=179, BW=180MiB/s (188MB/s)(900GiB/5127844msec); 0 zone resets
clat (usec): min=118, max=400029, avg=5542.57, stdev=5208.15
lat (usec): min=120, max=400047, avg=5561.90, stdev=5208.03
clat percentiles (msec):
| 1.00th=[ 4], 5.00th=[ 5], 10.00th=[ 5], 20.00th=[ 5],
| 30.00th=[ 5], 40.00th=[ 5], 50.00th=[ 5], 60.00th=[ 5],
| 70.00th=[ 6], 80.00th=[ 6], 90.00th=[ 7], 95.00th=[ 8],
| 99.00th=[ 22], 99.50th=[ 35], 99.90th=[ 87], 99.95th=[ 101],
| 99.99th=[ 144]
bw ( KiB/s): min= 6144, max=2981888, per=100.00%, avg=184084.36, stdev=65812.35, samples=10254
iops : min= 6, max= 2912, avg=179.74, stdev=64.27, samples=10254
lat (usec) : 250=0.10%, 500=0.02%, 750=0.01%, 1000=0.01%
lat (msec) : 2=0.01%, 4=1.37%, 10=95.23%, 20=2.08%, 50=0.88%
lat (msec) : 100=0.20%, 250=0.07%, 500=0.01%
cpu : usr=0.45%, sys=3.40%, ctx=931630, majf=0, minf=16
IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued rwts: total=0,921600,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs):
WRITE: bw=180MiB/s (188MB/s), 180MiB/s-180MiB/s (188MB/s-188MB/s), io=900GiB (966GB), run=5127844-5127844msec
From the TrueNAS GUI
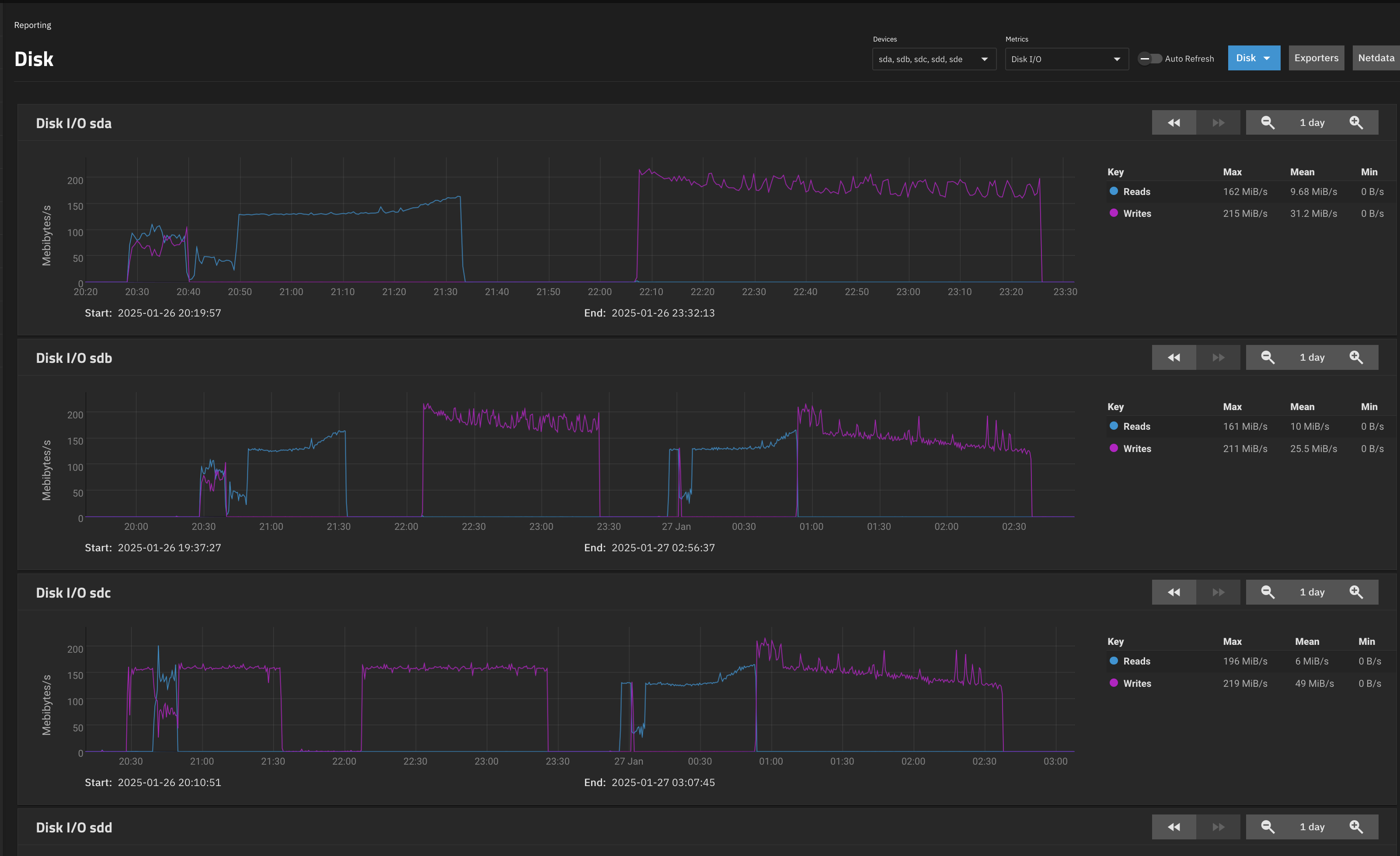
What I Learned
In general, I think I learned a whole lot of stuff about USB somethings i had no idea about before.
- Not all USB controllers handle sustained operations equally - the USB-C controller in my setup proved more stable
- It's worth checking for UASP when buying enclosures
- When passing through USB storage to VMs, direct disk passthrough is maybe more reliable than attempting to pass through the whole controller.
- Monitor temperatures during stress testing (I had journalctl and temp monitoring running throughout) something like
for drive in sda sdb sdc sdd; do echo "=== /dev/$drive ==="; smartctl -A /dev/$drive | grep -i temp; donefor temps.